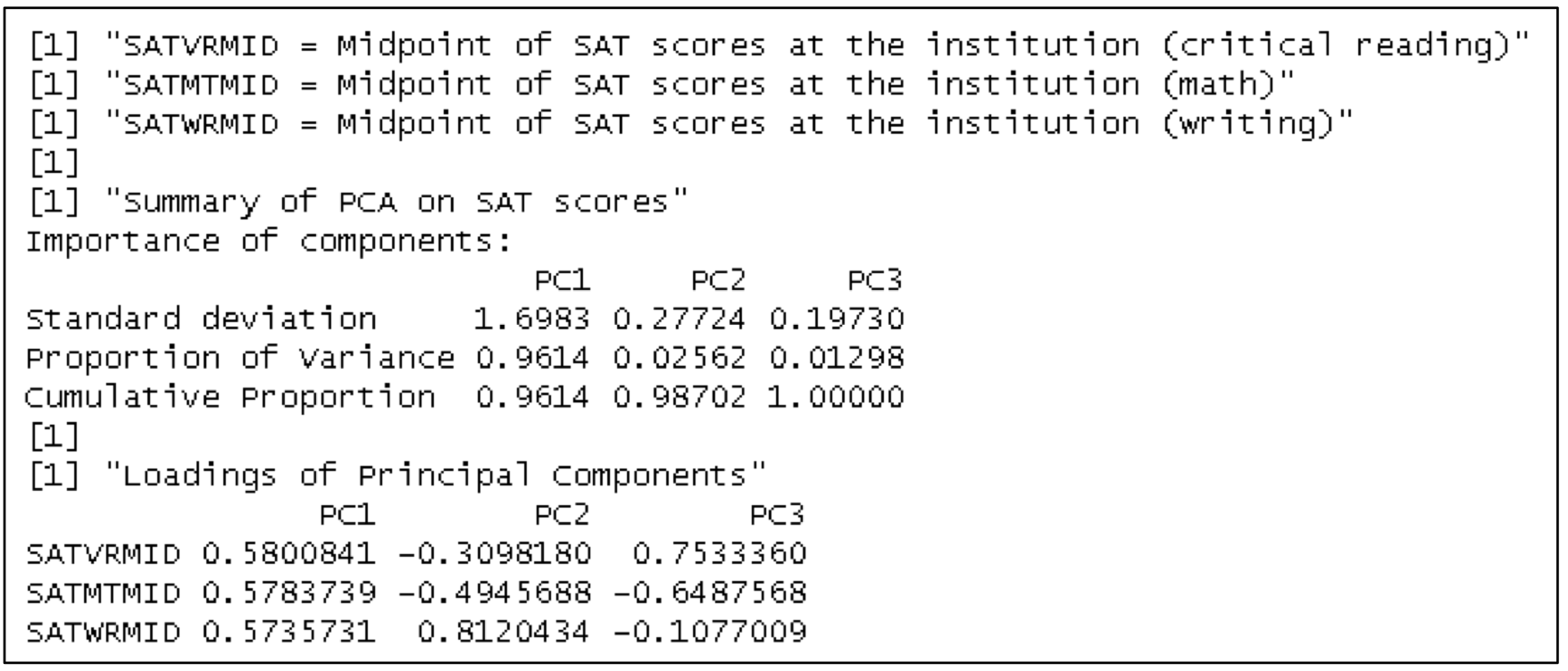
Task5 Perform a principal components analysis
Principal components analysis is a method to summarize high dimensional numeric data with fewer dimensions while preserving the spread of the data. It can be particularly helpful when variables are highly correlated. PCA finds orthogonal linear combinations of the input variables (which are typically centered and scaled) called principal components (PCs) that maximize variance to retain as much information as possible. The principal components are ordered according to their variance. The sum of their variances is the total variance explained. It is then common to look at the proportion of variance explained by each principal component to decide how many PCs to use.
Advantages
PCA could allow us to build a simpler model with fewer features. PCA can help visualize high-dimensional data to explore relationships between variables. PCA can help identify latent variables.
Disadvantages
Using a subset of the principal components results in some information loss. The principal components will be less interpretable than the original variable inputs. Although PCA reduces dimensionality in the model, the original variables must still be collected for future predictions, so no efficiency is obtained.
Task6 Construct a decision tree
When a decision tree is trained, it can become very large and include splits that are not particularly valuable for predictions on new data. When examining the fit of a tree, it is a good idea to try to prune a tree when it has many splits that do not improve performance. Pruning reduces the size of the tree, hopefully removing less valuable splits from the tree. This process reduces overfitting the tree on the training data, can lead to better predictions, and results in a simpler, more interpretable tree.
Task9 Discuss the bias-variance tradeoff
Bias is the expected loss caused by the model not being complex enough to capture the signal in the data. Variance is the expected loss from the model being too complex and overfitting to the training data.
With high variance (overfitting), the model will perform better on the training set than on a test set. With high bias (underfitting), the model will perform poorly on both the training set and the test set.
'SOA > PA' 카테고리의 다른 글
| SOA/ASA/PA 기출 및 내용정리 - 19.12.12시험(기록용) (0) | 2024.04.10 |
|---|---|
| SOA/ASA/PA 기출 및 내용정리 - 20.12.07시험(기록용) (0) | 2024.04.08 |
| SOA/ASA/PA 기출 및 내용정리 - 21.12.13시험(기록용) (0) | 2024.04.07 |
| SOA/ASA/PA 기출 및 내용정리 - 22.04.12시험 Task6~13(기록용) (0) | 2024.04.06 |
| SOA/ASA/PA 기출 및 내용정리 - 22.10.11시험 Task6~12(기록용) (0) | 2024.04.05 |